The AI Trust Meter
What if AI support tools were honest about uncertainty? An unsolicited design exploration inspired by Intercom Fin.
One confidently wrong AI answer doesn’t cost you a ticket. It costs you the agent’s trust in every answer after it.
How AI products handle uncertainty today
I audited how three leading AI-powered support and knowledge products present answers when they’re not confident. The pattern is consistent: fluency regardless of grounding, with a small disclaimer at the edge. The interface treats every answer as equally trustworthy because it has no other mechanism.
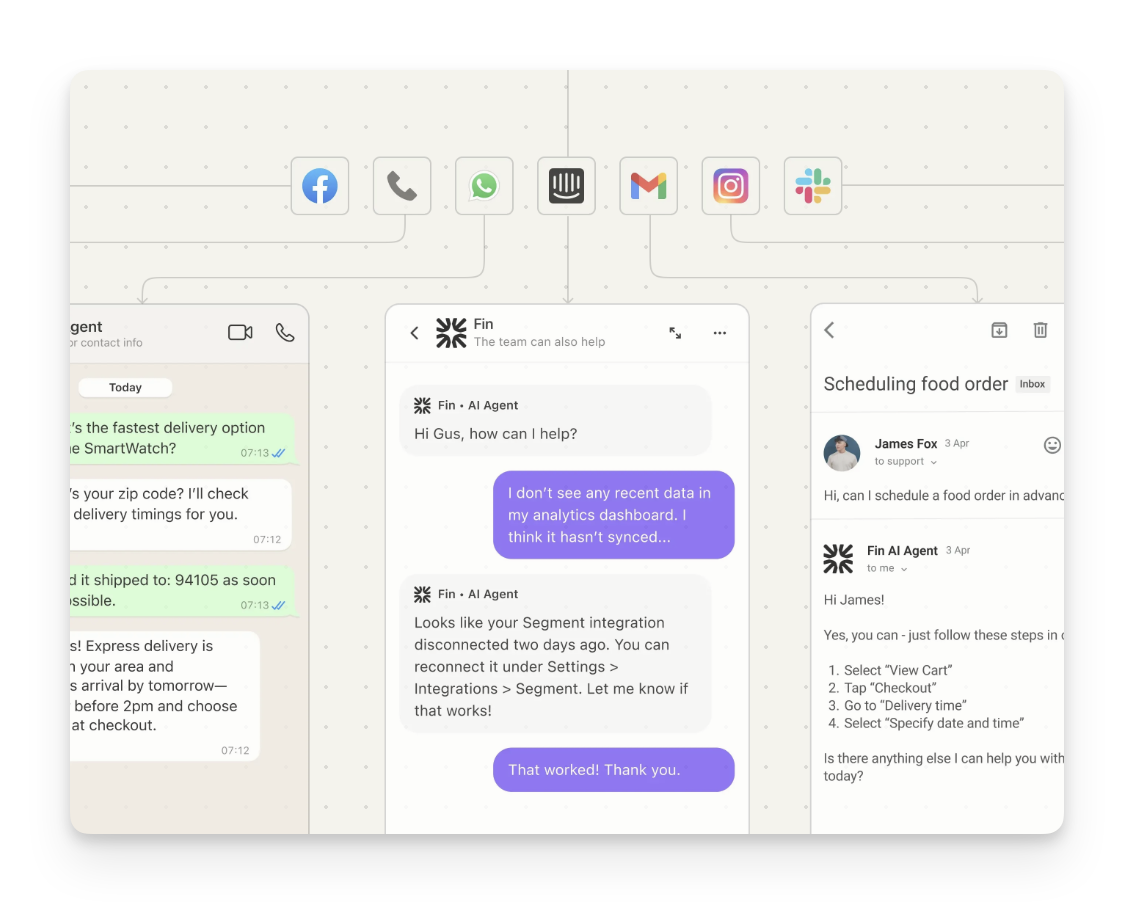
The only honesty mechanism shipping today is a disclaimer. Disclaimers are legal cover, not design.
The cost isn’t the error
Maya is a support agent. She handles 40+ tickets a day, measured on speed and accuracy. The AI assistant was added to make her faster — until it confidently told a customer they qualified for a refund they didn’t. Maya took the angry follow-up. Now she double-checks everything, and the AI saves her nothing.
“The cost of a wrong AI answer isn’t the error. It’s that every answer after it gets treated as a guess.”
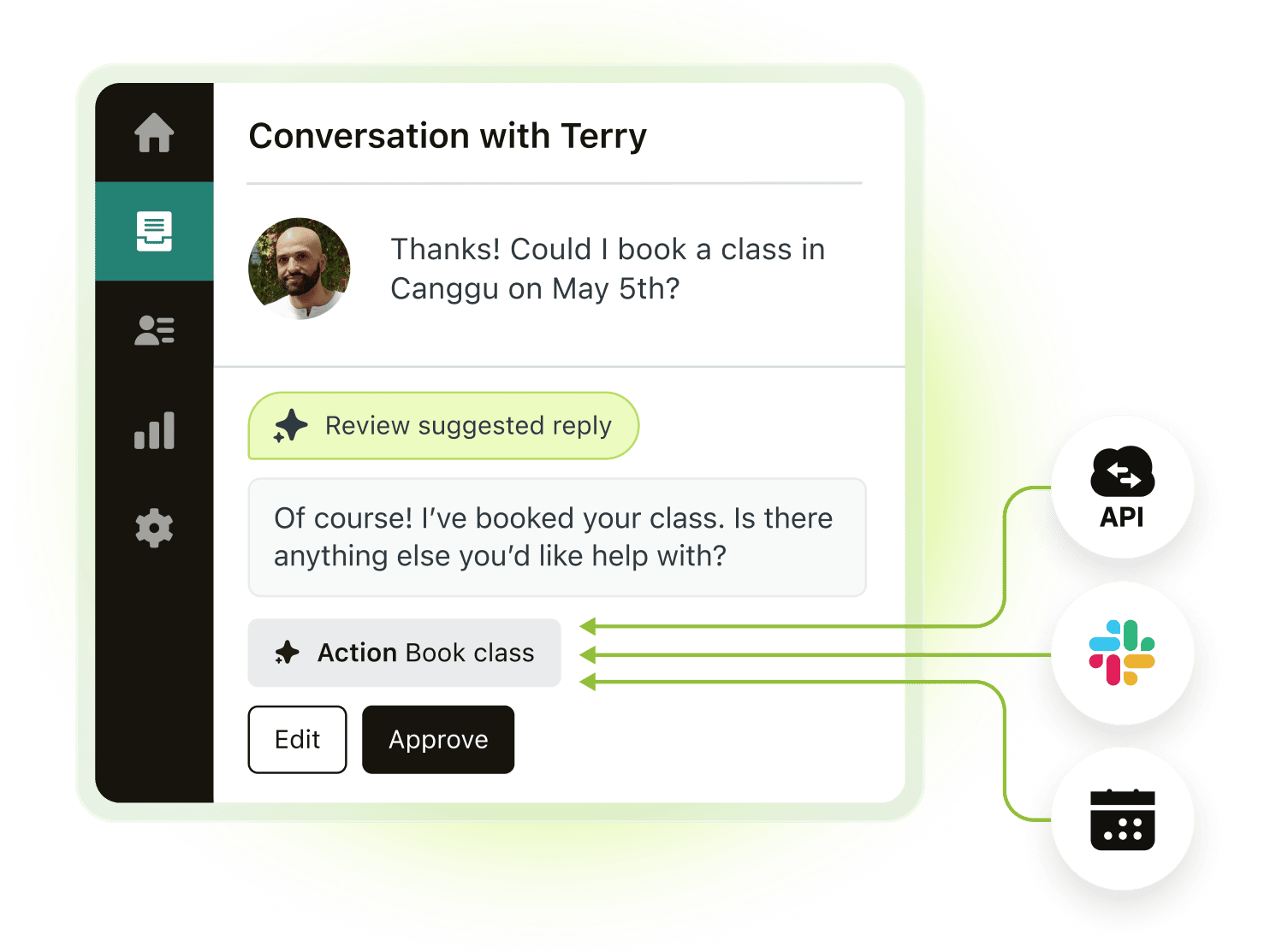
Three states. Three different jobs to do.
Each confidence state carries a different user need — and a different design obligation. These three stories are what the system is built to address.
“When the answer comes from policy, show me the source instantly so I can reply without fear.”
“When the AI is guessing, tell me BEFORE I send it. A guess should never wear the costume of a fact.”
“When it doesn't know, say so and point me to a human. I shouldn't apologize for its inventions.”
Three variants. One coherent system.
Each confidence state is a complete variant: distinct card surface, chip, source treatment, and action row — all derived from the same token set so they feel like a family, not three separate components.
Yes — monthly plans can be refunded in full within 30 days of the initial purchase, sent to the original payment method within 5–7 business days.
It appears the annual plan may be eligible for a discretionary refund in some cases, but this isn't guaranteed and is reviewed case-by-case.
I can't find a grounded answer to this in the Meridian docs. This needs a human to review.
A policy doc covering this specific scenario — the current knowledge base doesn't address it.
When the assistant can't ground an answer, the UI routes the agent to a person — instead of letting a guess reach the customer.
Why three segments instead of a percentage? LLMs can’t reliably self-report numeric confidence. “87% sure” would be fake precision — the exact dishonesty this system exists to remove. Three named states force the model to make a categorical judgment it can actually support, and give the agent language they can act on.
The same wrong answer, two interfaces
Both cards answer the same question about Dana's refund — a genuine gray area. One pretends to be sure. Watch how differently the honest answer feels when the interface stops pretending.
Yes — Acme is covered by Meridian's 30-day money-back guarantee, so Dana is eligible for a full refund. It'll be processed to the original payment method within 5–7 business days.
It's not clear-cut. Acme is past the standard 30-day window, and their annual plan isn't covered by it. There's a discretionary exception for annual customers, so a prorated refund may be possible — but it's case-by-case and not guaranteed.
The underlying answer is the same in both cases — a real gray area. Only the interface changed. And with it, whether the agent can tell a confident guess from a grounded fact before it reaches Dana.
Try it: you’re the agent
A support agent is mid-conversation with a customer. Ask the assistant a question — the answer returns with a visible confidence state, and what the agent can do with it changes based on how grounded it is.
You're Maya, a support agent at Meridian. Dana from Acme Logistics is asking about a refund. Ask the assistant — and notice how it behaves when it knows vs. when it's guessing.
Ask the assistant a question to see how the answer — and what you can do with it — changes with confidence.
The 5 docs the assistant can see▾
What I’d do next
The most important open question is behavioral, not visual: does the inferred-state friction actually reduce error rates, or does it just add a step agents learn to skip? I’d test this with a simple A/B — friction vs. no friction on inferred answers — and measure whether the review step changes insert behavior or just slows the workflow without improving accuracy. Speed and accuracy are in tension here, and the right answer depends on which the agent population is actually willing to trade.
The known limitation is scope. Confidence here is doc-grounding based: the system knows what’s in the knowledge base and flags when it’s reasoning beyond it. That works well for structured support — policies, FAQs, product docs. It breaks down for open-ended tasks where “grounded” doesn’t have a clean definition. This isn’t the right system for a general-purpose assistant; it’s the right system for domain-bounded, human-relayed answers.
Which points to where it generalizes. Any AI surface where a human relays the answer to someone else — support agents, legal assistants, healthcare coordinators, financial advisors using AI research tools — shares the same trust problem. The agent is accountable for the answer; the AI should make their accountability easier to exercise, not harder. The confidence-state pattern scales to any of those contexts.
Designed and built by Sanjana Gangishetty